Two weeks ago, we released Firefox Quantum to the world. It’s been a big moment for Mozilla, shaping up to be a blockbuster release that’s changing how people think and talk about Firefox. It’s also a cathartic moment for me personally: I’ve spent the last two years pouring my heart and soul into Quantum’s headline act, known as Stylo, and it means a lot to see it so well-received.
But while all the positive buzz is gratifying, it’s easy to miss the deeper significance of what we just shipped. Stylo was the culmination of a near-decade of R&D, a multiple-moonshot effort to build a better browser by building a better language. This is the story of how it happened.
Systems programmers have been struggling with memory safety for a long time. It is virtually impossible to develop and maintain a large-scale C/C++ application without introducing bugs that, under the right conditions and input, cause control flow to go off the rails and compromise security. There are those who claim otherwise, but I’m quite skeptical.
Browsers are the canonical example here. They’re enormous - millions of lines of C++ code, thousands of contributors, decades of cruft - and there’s enough at stake to create large incentives to find and avoid security-sensitive bugs. Mozilla, Google, Apple, and Microsoft have been at this for decades with access to some of the best talent in the world, and vulnerabilities haven’t stopped. So it’s pretty clear by now that “don’t make mistakes” is not a viable strategy.
Adding concurrency into the mix makes things exponentially worse, which is a shame because concurrency is the only way a program can utilize more than a fraction of the resources in a modern CPU. But with engineers struggling to keep the core pipeline correct under single-threaded execution, multi-threaded algorithms haven’t been a luxury any browser vendor could afford. There are too many details to get right, and getting any of them even slightly wrong can be catastrophic.
Getting details right at scale generally requires the right tools. For example, register allocation is a tedious process that bedeviled assembly programmers, whereas higher-level languages like C++ handle it automatically and get it right every single time. But while C++ effortlessly handles many low-level details, it just wasn’t built to guarantee memory and thread safety.
Could the right tool be built? In the late 2000s, some people at Mozilla decided to try, and announced Rust and Servo. The plan was simple: build a replacement for C++, and use the result to build a replacement for Gecko. In other words, Boil the Ocean - twice.
I am a firm proponent of incrementalism. I think the desire to throw everything away and start from scratch tends to be an emotional one, and generally indicates a lack of focus and clear thinking about what will actually move the needle.
This may sound antithetical to big, bold changes, but it’s not. Almost everything successful is incremental in one way or another. The teams behind revolutionary products succeed because they make strategic bets about which things to reinvent, and don’t waste energy rehashing stuff that doesn’t matter.
The creators of Rust understood this, and the language owes its remarkable success to careful and pragmatic decisions about scope and focus:
These tactics were by no means the only ingredients to Rust’s success. But they made success possible by neutralizing the structural advantages of C++ and allowing Rust’s good ideas - particularly its control over mutable aliasing - to reach production code.
Rust is a big leap forward for the industry, and should make its creators proud. But the grand plan for Firefox required a second moonshot, Servo, with an even steeper path to success.
At first glance, the two phases seem analogous: build Rust to replace C++, and then build Servo to replace Gecko. However, there’s a crucial difference - nobody expects the Rust compiler to handle C++ code, but browsers must maintain backwards-compatibility with every single webpage ever written. What’s more, the breadth of the web platform is staggering. It grew organically over almost three decades, has no clear limits in scope, and has lots of tricky observables that thwart attempts to simplify. Reimplementing every last feature and quirk from scratch would probably require thousands of engineer-years. And Mozilla, already heavily outgunned by its for-profit rivals, could only afford to commit a handful of heads to the Servo project.
That kind of headcount math led some people within Mozilla to dismiss Servo as a boondoggle, and the team needed to move fast to demonstrate that Rust could truly build the engine of the future. Rather than grinding through features indiscriminately, they stood up a skeleton, stubbed out the long tail, and focused on reimagining the core pipeline to eliminate performance bottlenecks. Meanwhile, they also invested heavily in community outreach and building a smooth workflow for volunteers. If they could build a compelling next-generation core, they wagered that a safe language and more-accurate specifications from WHATWG could allow an army of volunteers to fill in the rest.
By 2015, the Servo team had built some seriously impressive stuff. They had CSS and layout engines with full type-safe concurrency, which allowed them to run circles around production browsers on multi-core machines. They also had an early prototype of a full-GPU graphics layer called WebRender which dramatically lowered the cost of rendering. With Firefox falling behind in the market, Servo seemed like just the sort of secret sauce that could get us back in the game. But while Servo continued to build volunteer momentum, the completion curve still stretched too far into the future to make it an actionable replacement for Gecko.
Whenever a problem seems impossibly hard, tackling it incrementally is a reliable way to gain traction. So near the end of 2015, some of us started brainstorming ways to use parts of Servo in Firefox. Several proposals floated around, but the two that seemed most workable were the CSS engine and WebRender. This post is about the former, but WebRender integration is also making exciting progress, and you can expect to hear more about it soon.
Servo’s CSS engine was an attractive integration target because it was extremely fast and relatively mature. It also serves as the bridge between the DOM and layout, providing a beachhead for further expansion of Rust into rendering code. Unfortunately, CSS engines are also tightly coupled with DOM and layout code, so there is no clean API surface at which to cut. Swapping it out is a daunting task, to say nothing of the complexities of mixing in a new programming language. So there was a lot of skepticism and some chuckling when we started telling people what we were up to.
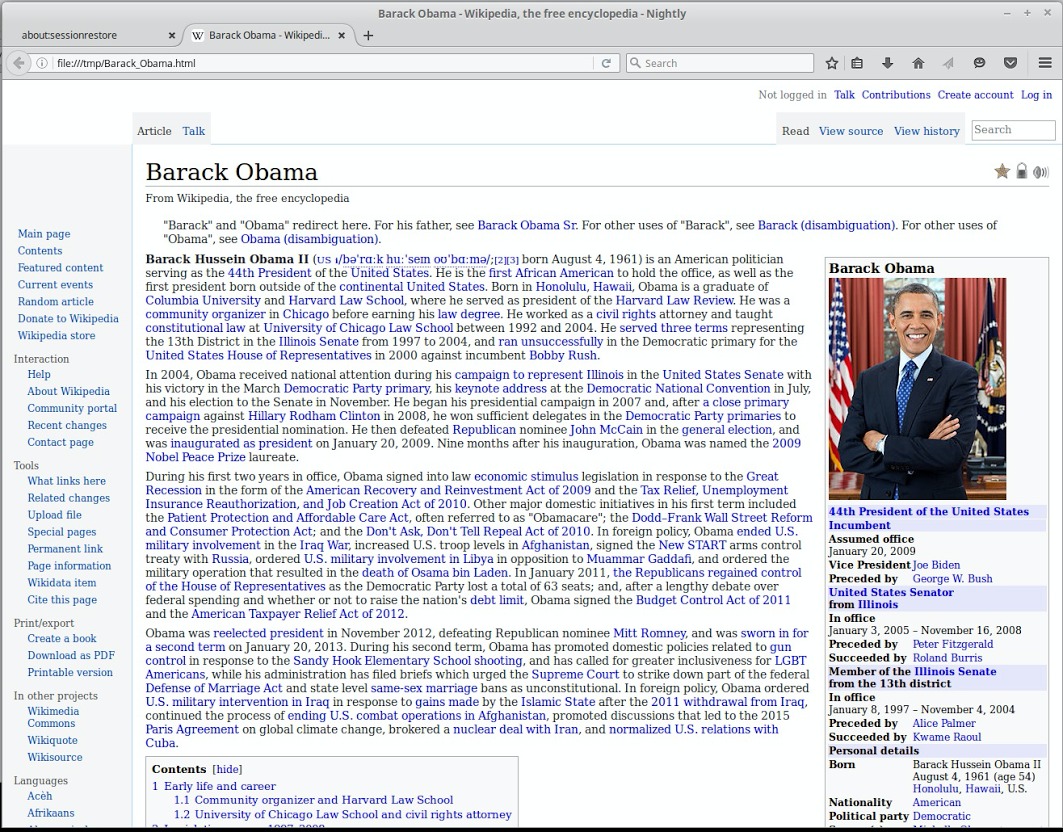
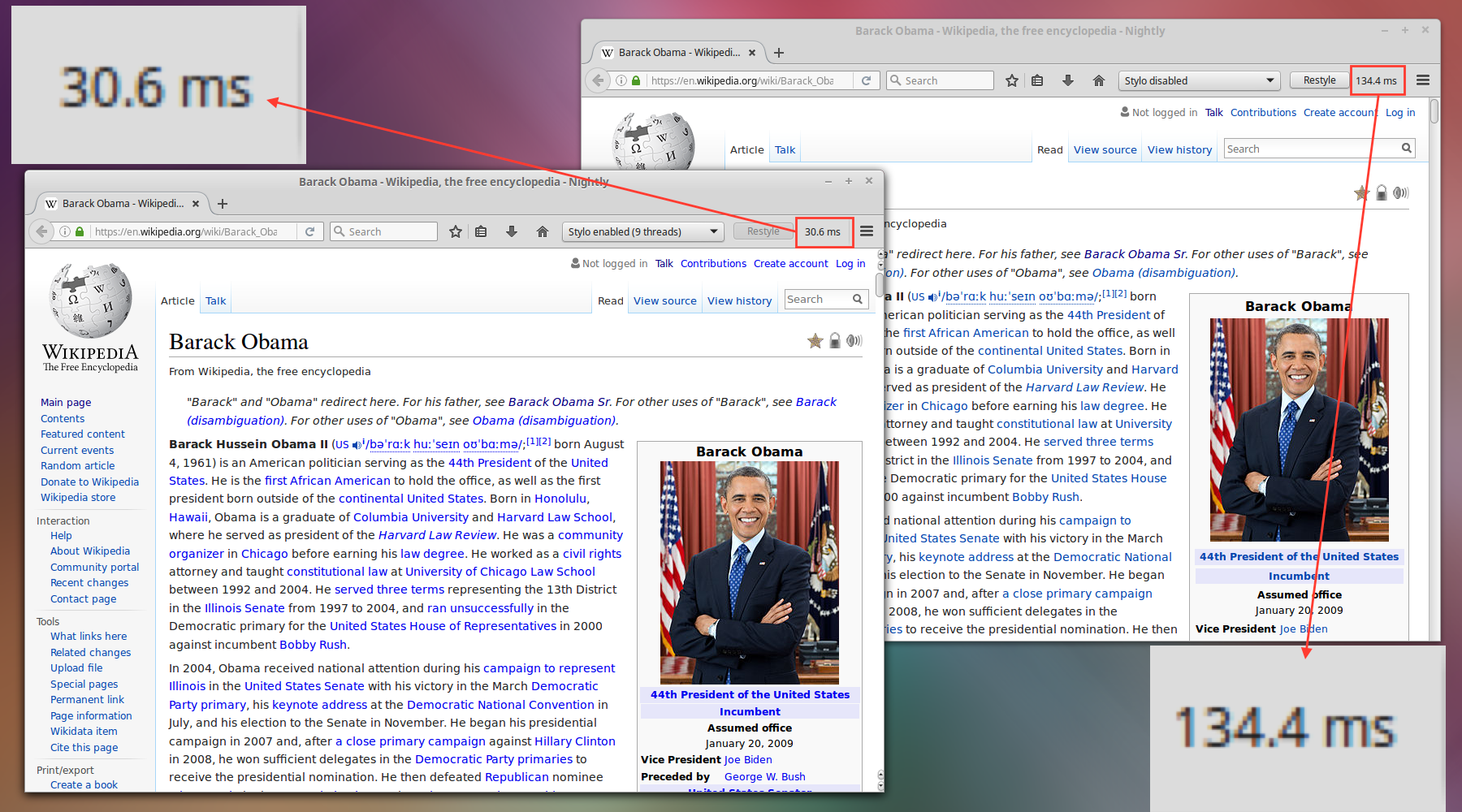
But we dove in anyway. It was a small team - just me and Cameron McCormack for the first few months, after which point Emilio Cobos joined us as a volunteer. We picked our battles carefully, seeking to maintain momentum and prove viability without drowning in too many tricky details. In April 2016, we got our first pixels on the screen. In May, we rendered Wikipedia. In June, we rendered Wikipedia fast. The numbers were encouraging enough to convince management to launch it as part of Project Quantum, and scale up resourcing to get it done.
Over the next fifteen months, we transformed that prototype into the most advanced CSS engine ever built, one which harnesses the guarantees of Rust to achieve a degree of parallelism that would be intractable to replicate in C++. The technical details are too involved to get into here, but you can learn more about them in Lin Clark’s excellent writeup, Manish Goregaokar’s release-day post, or my high-level overview from last December.
Stylo shipped, first and foremost, thanks to the dedication and passion of the people who worked on it. They tackled challenge after challenge, pushing themselves to the limit and learning whatever new skills or roles were required to move things forward. The core team of staff and volunteers spanned more than ten countries, and worked (quite literally) around the clock for over a year to get it done on time.
But the real team was also much larger than the set of people working on it full-time. Stylo needed the expertise of a lot of different groups with different goals. We had to ask for a lot of help, and we rarely needed to ask twice. The entire Mozilla community (including the Rust community) deeply wanted us to succeed, so much so that almost everyone was willing to drop what they were doing to get us unblocked. I originally kept a list of people to thank, but I gave up when it got too big, and when I realized the countless ways in which so many Mozillians helped us in some way, big or small.
So thank you, Mozilla community. Stylo is a testament to your hard work, your ingenuity, and your good-natured, scrappy grit. Be proud of this release - it’s a game-changer for the open web, and you made it happen.
{kind=link}
{kind=link}
{kind=link}